RでTwitterのツイート分析(ログ取得編)
最近Rに関して更新しておらず、更新せねばと思っていました。
そんなことを漠然と考えていたら、「久しぶりにRで新しいことをやろう!!」とふと思いつき、何が出来るだろうかと思案していました。
そんな時に思いついたのが、Twitterのログ解析です。
昔、後輩と一緒に取り組んだことがありますが、上手くいかず後輩には申し訳ないと思ったままリベンジを忘れていました。
Rでやらなくても、ログ取得用のサービスとkh_coderなどを組み合わせて活用すると大体のことは出来るものです。
しかし、R好きとして、どうしてもRでやってみたい!!
しかも、上手くすればテキストデータ以外も取得して分析できるかも!!
こんなことを考え出したら、止まらないものです。
そこで、今回はとりあえずRを使ってTwitterのログ取得してみたいと思います。
まずは、Twitterの方で新しいアプリを作るらしい。
そんなに難しくないのでテンポよく行ってみよう!!
まず、前提条件から
Twitterアカウントを作成しておいてください。
既にお持ちの方はそのアカウントでも結構です。
あと、Twitterのアカウントに電話番号が登録できます。
この電話番号も登録しておいてください。
以上の前提を元に進めていきます。
まず、下記のURLにいってください。
そうするとこんな画面が出てきます。
とりあえず、sign inします。
すると画面上部にこんなのが表示されます。

ここの「Create New App」をクリックします。
すると今度はこちらの画面。

各項目に関して
Name
この回の作業は簡単にいうとTwitter関連のアプリを作っているようなものです。
そのアプリの名前をつけなければいけません。
過去に誰かが使用している名前だとエラーが出ます。
私は「TwitterText_Mining_Data」としましたが、これと同じ入力をすると作成できないので、ここには自分独自の名称を入れてください。
Description
このアプリがどんなアプリかの説明です。
自分が複数アプリを作成した場合に、見分けがつくように書くものです。
私と同じ文言を入れても作成可能です。
Website
画像と同じものを入力してください。
さて、入力が終了したら一番下の「Create your Twitter appliation」をクリックします。
するとこんな画面になります。
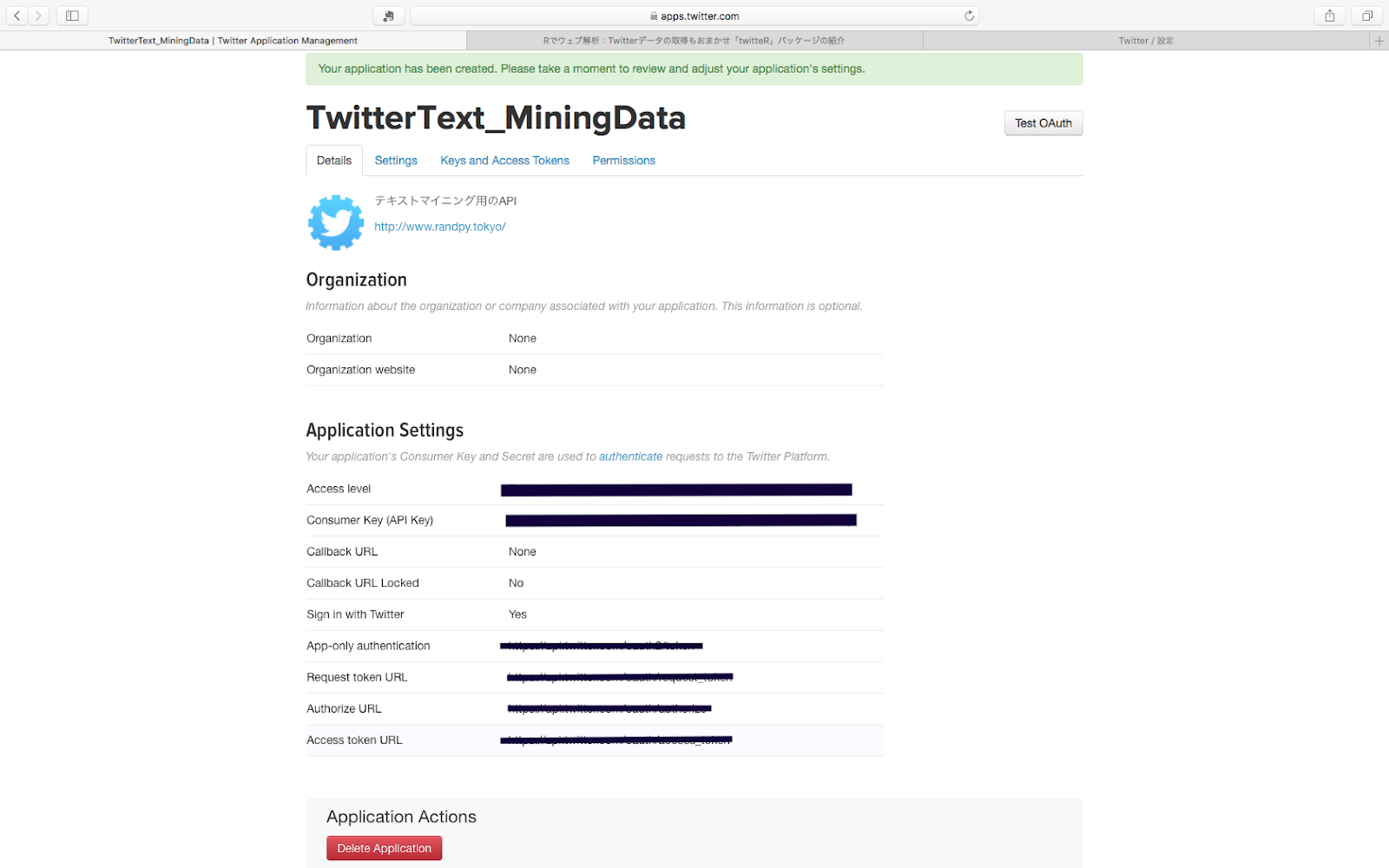
URLなどは塗りつぶしましたが、こんな感じの画面になると思います。
そうしたら、まず一番左の「Permissions」をクリックします。
するとこんな画面になるので、一番下の「Read, Write and Access direct messages」にチェックを入れます。
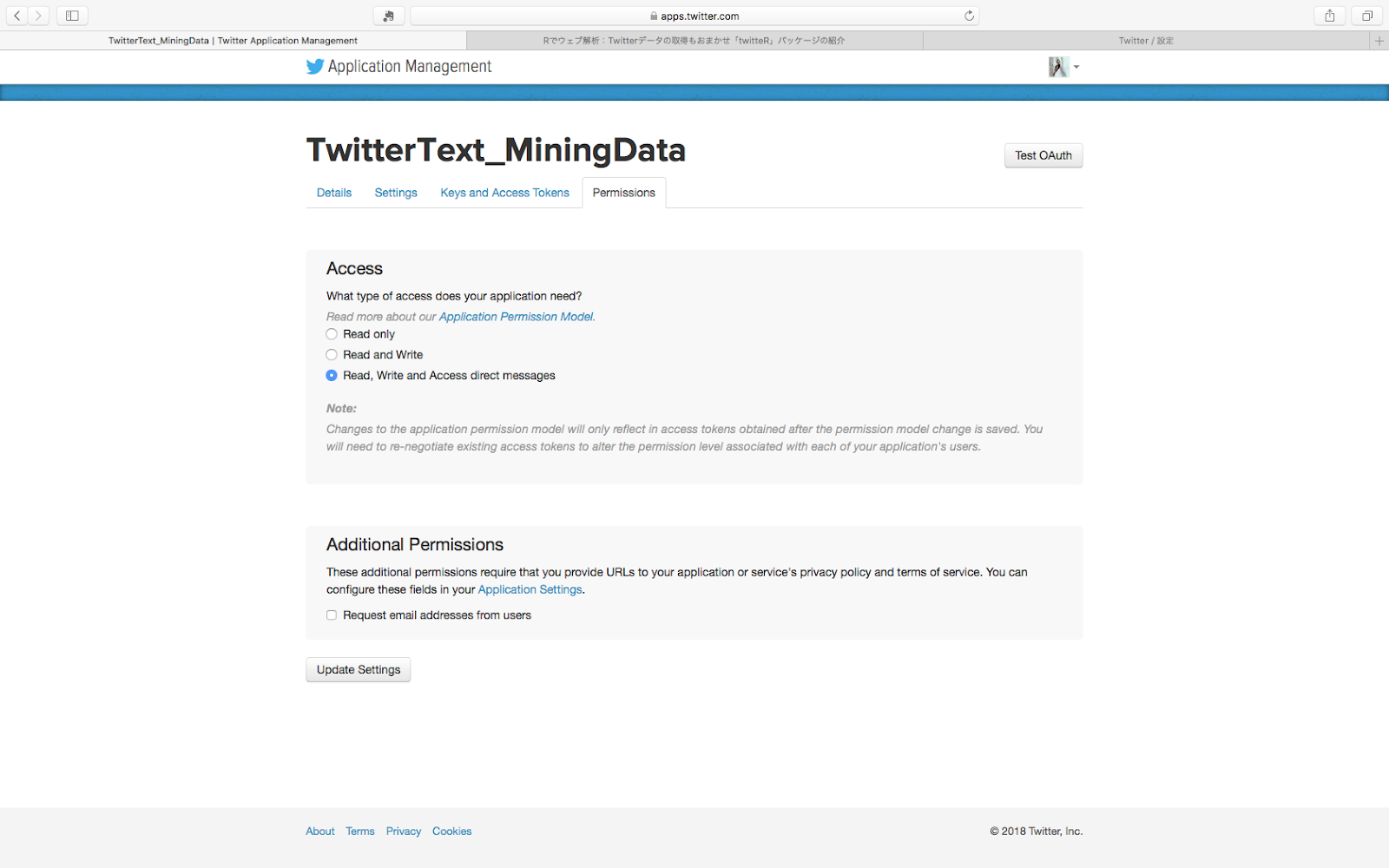
そうしたら次は「Permissions」のお隣の「Keys and Access Tokens」をクリックします。この画面にRとこのアプリを連携させるのに必要なデータが書いてあります。
私のものは黒塗りにしてありますが、あなたの画面には表示されているはず!!
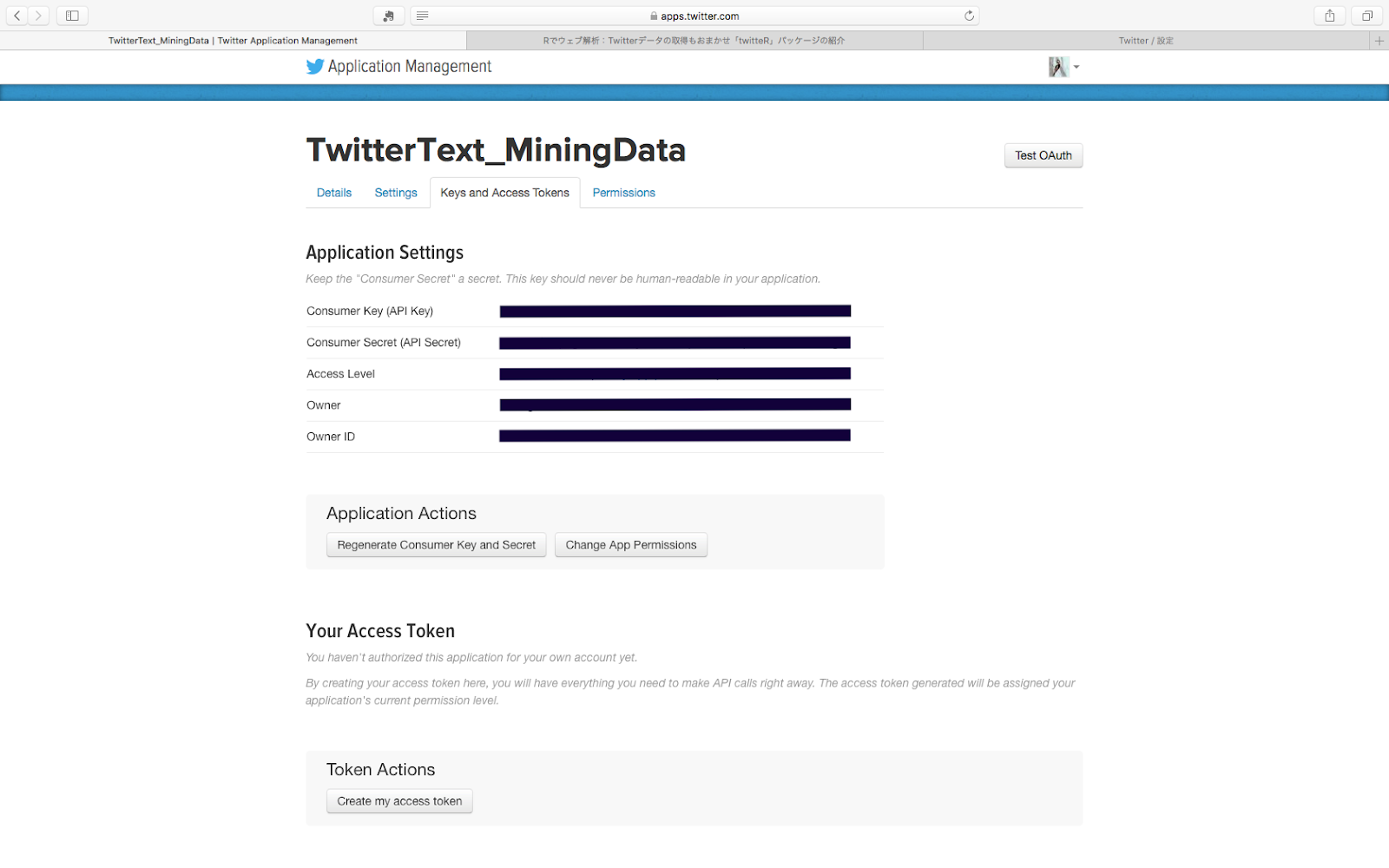
さて、ここからはRでの操作にさります。みんな大好きRを起動しましょう。
今回使うパッケージは”rtweet”です!!
本当は"twitterR"というパッケージを使おうと思ったのですが、インストールがなぜか上手くいかず、諦めてこちらのパッケージにしました。1つの手段がダメでも大体が利くのがRの良いところです。
とりあえず、パッケージをインストール&libraryしましょう。
install.packages("rtweet",dependencies=TRUE)
library(rtweet)
続いては、今後の先ほどのアプリ作成した画面に表示されていた情報を入力します。
APPNAME ="アプリ作成時に入力したNameを入力"
CONSUMERKEY = "Consumer Key (API Key)をコピペ"
CONSUMERSECRET = "Consumer Secret (API Secret)をコピペ"
この作業ではAPPNAEMに先ほど自分が作ったアプリ名を代入している作業だと思ってください。
次は、その代入してものを使って以下のコードです。
twitter_token = create_token(
app=APPNAME,
consumer_key = CONSUMERKEY,
consumer_secret = CONSUMERSECRET)
これは、皆さんもそのまま入力してください。
このコードを実行するとTwitter側に先ほど作ったアプリとTwitterアカウントを連携させるかどうかの同意を確認する通知が来ます。
なので、連携を選んで確認してください。
そうしたら、実際にツイートを取得してみます。
コードはこちら
tweet_npur = get_timeline("アカウントID" , token = twitter_token)
アカウントIDという表現が正しいかは分かりませんが、@以降の部分ですね。
@を入力する必要はありません、
例)@abcdさんのデータを取得したい場合
tweet_npur = get_timeline("abcd" , token = twitter_token)
注意点)
対象アカウントに鍵がかかっている場合、相手からのフォロー承認が必要です。
ちなみにこのコードでは、指定したアカウントの全てのツイートを取得します。
最新から任意の数のツイートを取得したい場合は、"n = "の引数を追加してください。
例)最新から10ツイートを取得したい場合
tweet_npur = get_timeline("アカウントID" , n = 10, token = twitter_token)
これでデータは取得できているので、実際にどのような項目のデータが取得されたか確認してみましょう。

想像以上に大量の項目のデータが取得されていてびっくりです。
この中で、ツイートのテキストデータを含む項目は、5列目の"text"です。
以下のコードでtextの内容を確認できます、
tweet_npur$text
だいぶ長くなってしまたが、今回はここまでです。
次回は、このデータを元に実際にテキストマイニングをいろいろとやってみましょう。
しかし、これだけデータが集まるとテキストマイニング以外の分析もできそうでワクワクしますね。
いや〜、これで私も晴れてインターネットストーカーへの第一歩を踏み出したのかもしれない。



コメント
コメントを投稿