subsetで必要なデータだけを、取り出す。
最近は男女差を比較したい時でも、性別の欄が2値のデータでない場合があります。
私もGoogleFormを用いてアンケート調査を行った時、フェイスシートでの性別の欄にはその他を準備しました。
その結果、回答数約200中4件ほどLGBTQの方の回答もありました。
性別を独立変数に用いる場合、LGBTQの人をどのように扱っていくかについてはここでは触れませんが、今後しっかりと考えなければいけないことだと思います。
ここでは、性別に「その他」という回答が含まれるデータから、男性と女性の回答だけを抜き出して分析する方法を紹介します。
データを抜き出す方法として、subset関数を用います。
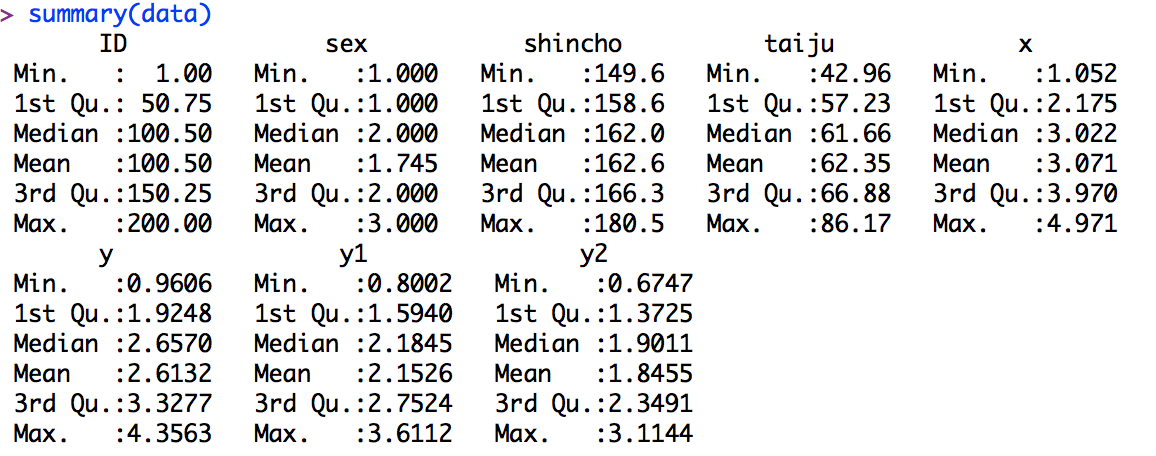
今回は以下のデータを使います。

各変数は以下のようになっています。
ID:回答者のIDです。入力時に識別するだけで、それ以上の意味はありません。
sex:性別の解答欄です。1が男性、2が女性、3がその他となっています。
shincho:身長を想定したデータです。
taiju:体重を想定したデータです。
x.y.y1.y2は適当な変数なので、意味は考えないでください。
乱数発生で作った、人工データなので「身長のデータ小数点以下の桁多くないか?」みたいな細かい点は気にしないでください。
subsetの使い方は簡単です。
こんな感じです。
男性だけ抽出するのであれば

data2 <- subset(data,data$sex==1)
となります。
複数条件(男性と女性や男性かつ身長が高いなど)を指定する場合は、&と|を使います。
&はANDを意味し、「〜かつ〜」という条件です
|はORを意味し、「〜または〜」という条件です。
今回の例では、「男性または女性」なので(data$sex==1 | data$sex==2)となります。
元のデータセットから必要なデータを抽出し適宜分析を行っていくのがRです。
データ抽出には、いろいろな方法がありますが一番簡単なのがsubsetだと思います。


コメント
コメントを投稿