Rで階層的クラスター分析をやる
「階層的クラスター分析とはなんぞや」と思う方は、頑張って調べてください。
調べるのは大切ですが、私は実際にやりながらの方が理解できると思いますので、ここでは階層的クラスター分析の実際のやり方を紹介しようと思います。
私の適当な理解だと、「参加者がどの様な群に分かれるか知りたいが、想像がつかないので探索的に調べてみたい」と言うときに階層的クラスター分析を行うと思います。
では、実際にやってみましょう。
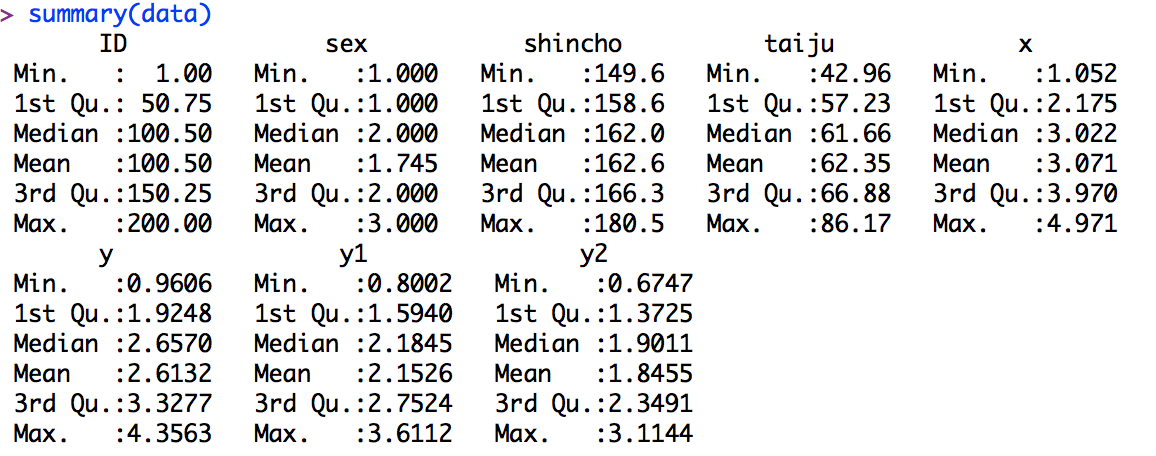
基本情報
データ名:data
変数:
ID:回答者のIDです。入力時に識別するだけで、それ以上の意味はありません。
sex:性別の解答欄です。1が男性、2が女性、3がその他となっています。
shincho:身長を想定したデータです。
taiju:体重を想定したデータです。
x.y.y1.y2は適当な変数なので、意味は考えないでください。
実際にはこんな感じです。

今回はx.y.y1.y2の4つの変数で、参加者が何群に別れそうかを見てみます。
まず、クラスター分析に用いる変数だけのデータセットを作成します。
data_set <- data[,c("x","y","y1","y2")]
そして、distオブジェクトに変換します。
d <- dist(data_set)
最後に二乗距離を使って分析します。
方法はウォード法です。
さらに、今回は式全体をplot関数で囲んでいるので、図の出力もさせています。
plot(hclust(d^2,method="ward.D"),hang=-1)
以下のように、結果が出力されます。

サンプル数が200ですから最後は真っ黒ですね。
この結果をどのように見るかです。
まず、この場合の参加者たちは大きく2つの群に分かれることが分かります。
ピンクのラインが入っている場所が、そうです。

次のさらにその中で2つに分岐しているため、水色の線の位置では4群と言えます。

まぁ、さらに細かくみていけば、次は一番右の群が2つに分岐しているので、そこを見て5群とも言えますが、
水色の4群が妥当ですかね。
こんな感じで、サンプルが何群に分かれそうかを探索的に調べることができます。
しかし、これはサンプル数が200程度だからできることなので、ビッグデータを探索的にクラスターをかけるってことをすると、コンピュータに相当のスペックが必要になります。
大学生の卒論ではそんなことは気にしなくても大丈夫ですが。
実際に、階層的クラスター分析を行った感想としては、こんなに綺麗に分かれないと思います。
どこで切って南郡にするかは、研究者の主観になってしまうので、これを目安に何パターンか非階層的クラスター分析を行って最適解を探すのがいいと思います。
では、次は非階層的クラスター分析を行ってみましょう!!



コメント
コメントを投稿