Rでの、データの基礎統計量の算出(summary,describe)
Rでの分析をする際に、まず最初にデータの基礎統計量が算出する必要があります。
Rに元々入っている関数では、summary関数を用います。
データは擬似的に作成した、データを用います。(データ名は「data」です)
まず、Rに標準装備されているsummary関数を使ってみます。
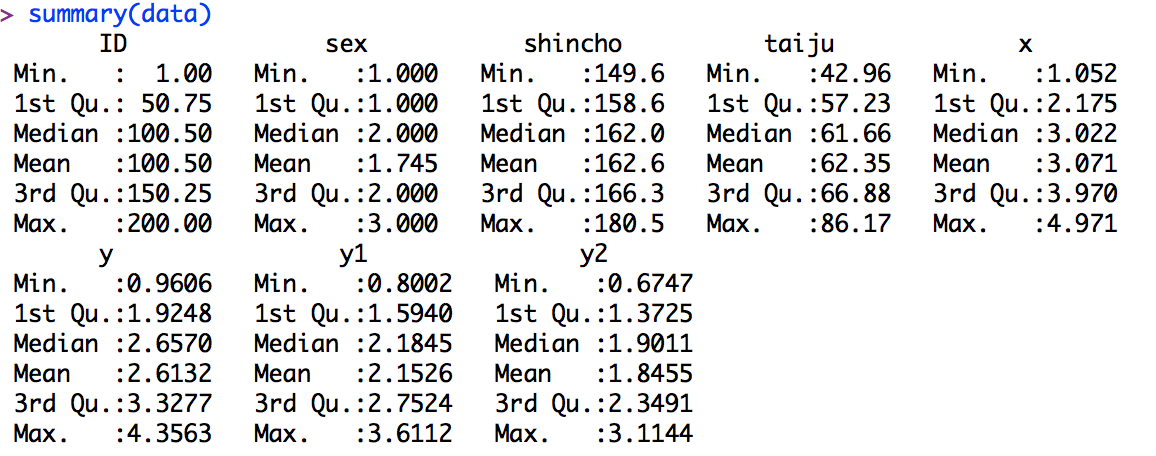
結果はこのように出力されます。
Rでは結果が英語で出力されます。各項目の日本語訳は以下のようになります。
Min.最小値
1st. Qu.第一四分位
Median中央値
Mean平均値
3rd Qu.第三四分位
Max.最大値
summary関数では、代表値は簡単に分かります。
しかし、心理系の論文を書くのであれば標準偏差が知りたいところです。
そこで、psychパッケージをインストール&libraryして、describe関数を使います。
install.packages("psych")
library(psych)
このパッケージで心理系の分析の基本ができるようになります。
では、実際にdescribe関数を使っていましょう。
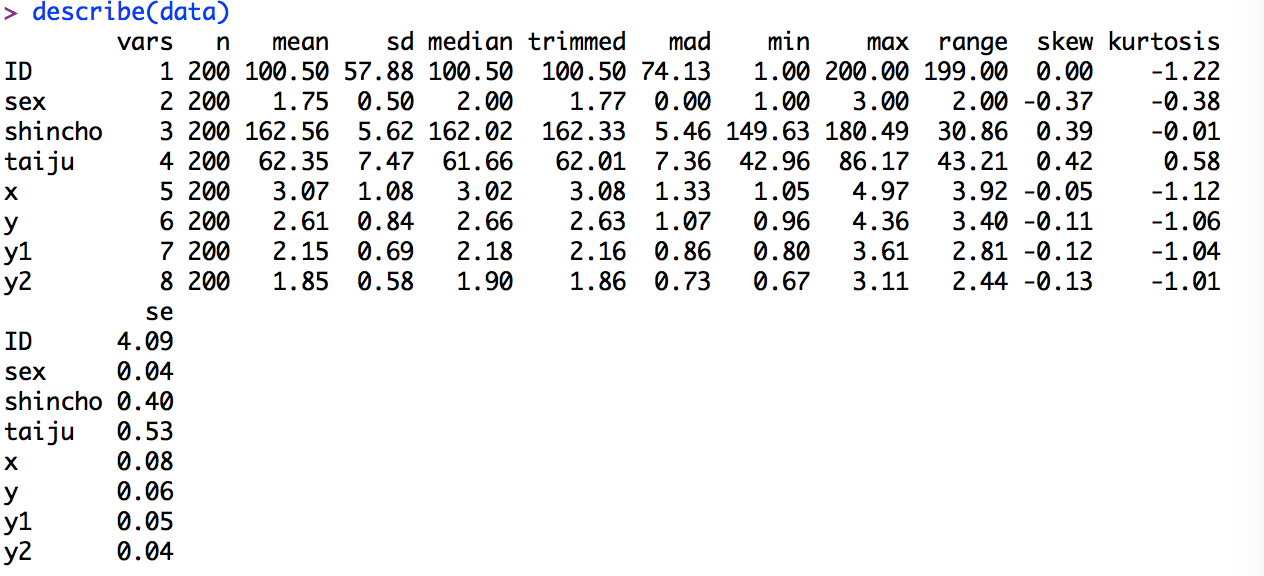
結果はこのように出力されます。
待望の標準偏差が出力されました。
結果が折り返されて表示されているので、少しみづらいですね・・・
vars:列番号
n:サンプル数
mean:平均値
sd:標準偏差
median:中央値
trimmed:トリムされた平均値
mad:中央絶対偏差値
min:最小値
max:最大値
range:レンジ
skew:歪度
kurtosis:尖度
se:標準誤差
情報量は多いですが、いくつ理解できて活用できるかは技量次第ですね。
分からない、用語は自分で検索してみてください。



コメント
コメントを投稿