Rで非階層的クラスター分析をやる
前回、階層的クラスター分析を紹介したので、今回は非階層的クラスター分析を行います。
先行研究でクラスター数が分かっている、もしくは想定される場合は非階層的クラスター分析から開始できますが、そうでない場合は階層的クタクター分析でクラスター数に目安をつけておく必要があります。
今回は、前回行った階層的クラスター分析の結果を元にやっていきます。
ここから、見て意味が分からない方は前回の階層的クラスター分析を見てください。
前回、x.y.y1.y2の4つの変数で、参加者が4群に分かれそうなことが分かりました。
そこで、実際にどのような4群なのかを見ていきましょう。
今回は非階層的クラスター分析をplyrパッケージのkmeans関数を用いて行います。
まず、いつも通りパッケージのインストールと読み込みを行います。
install.packages("plyr”)
library(plyr)
前回と同じく、クラスター分析したい項目だけのデータセットを作成します。
data_cl <- data[,c("x","y","y1","y2")]
そして、kmeans関数で分析を実行させます。
(k <- kmeans(data_cl , 4))
式全体が()で括られているのは、分析結果をkというオブジェクトに代入しているので、そのままでは結果が表示されないため、結果を呼び出すためのものです。
kmeans関数の基本は以下のようになっています。
基本式:kmeans(データフレーム,クラスター数)
以下、任意のオプション
iter.max : 繰り返しの最大回数。デフォルトは N=10。
nstart : ランダムに初期値を設定する場合のパラメータ。初期値を変更したい場合に用いる。試行回数。何通りの初期値を設定するかを指定する。k-means法は初期値依存という短所があります。そのため、時間とPCのスペックが許す限りnstartの回数を大きくした方が良いようです。初期値は最大でサンプル数-1までだと思います。同じ条件式で複数回分析を行い結果が同じであればさらに万全です。
algorithm : 利用するアルゴリズムを Hartigan-Wong", "Lloyd", "Forgy", "MacQueen"の中から選べる。デフォルトは "Hartigan-Wong"(通常、この"Hartigan-Wong"が最も良い結果を出すといわれている)。
結果はこのように出力されます。
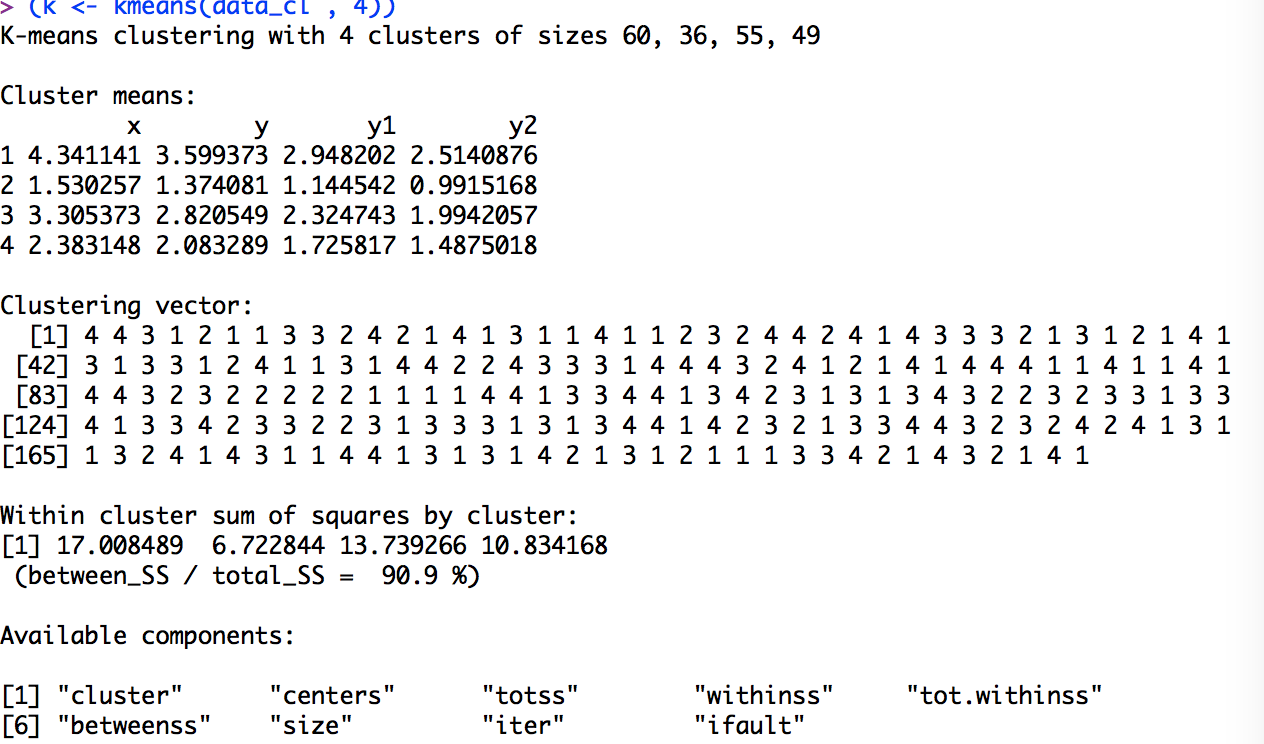
K-means clustering with 4 clusters of sizes という箇所が、各クラスターに何人ずつ分かれたかです。
Cluster means:は各クラスターの各変数の平均値を示しています。
Clustering vector:は各サンプルがどのクラスターになったを示しています。
その下は、よく分かりません!!
ちなみに、同じ式でもう一度分析した結果がこちらです。

さぁ、違いは何でしょうか?
K-means clustering with 4 clusters of sizesで書かれている各クラスターのサンプル数の順番が違います。
これは、初期値をどこに取ったかによる違いです。各クラスターは数字で表現されていますが、これはただの名義なので、意味はないのです。
そのため、一見違う結果に見えますが、各クラスターの人数が同じであれば同じ結果と言えます。
実際には、各サンプルがどのクラスターに分けられているかも見た方がいいですが、面倒ですからね。
Excelを使ったりすれば、簡単にできそうですが。
次は、どのサンプルがどのクラスターに分類されたかが分かるように、元データにどのクラスターか分かるように新しい変数を作って代入します。
data$cluster <- k$cluster #元データにクラスター分析の結果を入れる。

新しいclusterという変数が作られて、その中にどのクラスターかを示す数字が入っています。
これで、クラスター毎に分けて分析できます。
しかし、それぞれのクラスターがどのような特徴を持っているのかが分かりません。
cluster meansを見れば、分かるのですが理解がむずかしいですよね。
そこで、各クラスターの平均値を箱ひげ図で出力してみます。
今回は4クラスターに分かれてるので、2*2で1枚のシートで出力します。
par(mfrow=c(2,2)) #2*2で図を配置してくれる。
boxplot(data$x~data$cluster,main="x",xlab="クラスター”)
boxplot(data$y~data$cluster,main="y",xlab="クラスター")
boxplot(data$y1~data$cluster,main="y1",xlab="クラスター")
boxplot(data$y2~data$cluster,main="y2",xlab="クラスター”)
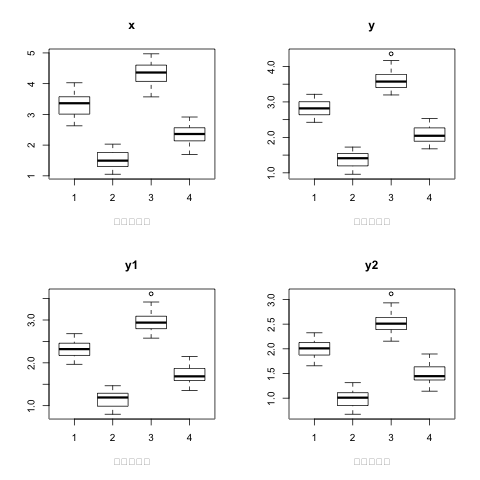
こんな感じで出力されました。
ラベルが1つ文字化けして、四角になってしまっていますね。
まぁ、今回は気にしないでおきましょう。
ちなみに、ggplot2などを使うともっと綺麗な図が書けたりします。
これで、各クラスターの特徴が見えてきましたね。
さて、次問題は各クラスターの平均値に有意な差があるかです。
今回は4つのクラスターなので、分散分析ですね。
applyファミリーを活用して、一気に分析してみます。
lapply(as.data.frame(data),function(w)oneway.test(w~data$cluster))
この式は独立変数をdata$clusterに固定して、dataの中の全ての変数で分散分析を行っています。
なので、いらないところまで分析してくれています。
それが気になる方は、クラスター分析に用いた変数だけのデータセットを用いて、分析すると必要な分散分析だけになります。
lapply(as.data.frame(data_cl),function(w)oneway.test(w~k$cluster))
こんな感じです。

スッキリしていていいですね。
しかし、ここでも問題があります。
そうです。多重比較をしてくれていないのです。
そこで、式を少し改造してこんな感じにしてみた。
lapply(as.data.frame(data_cl),function(w)pairwise.t.test(w,k$cluster, p.adj = "bonf"))
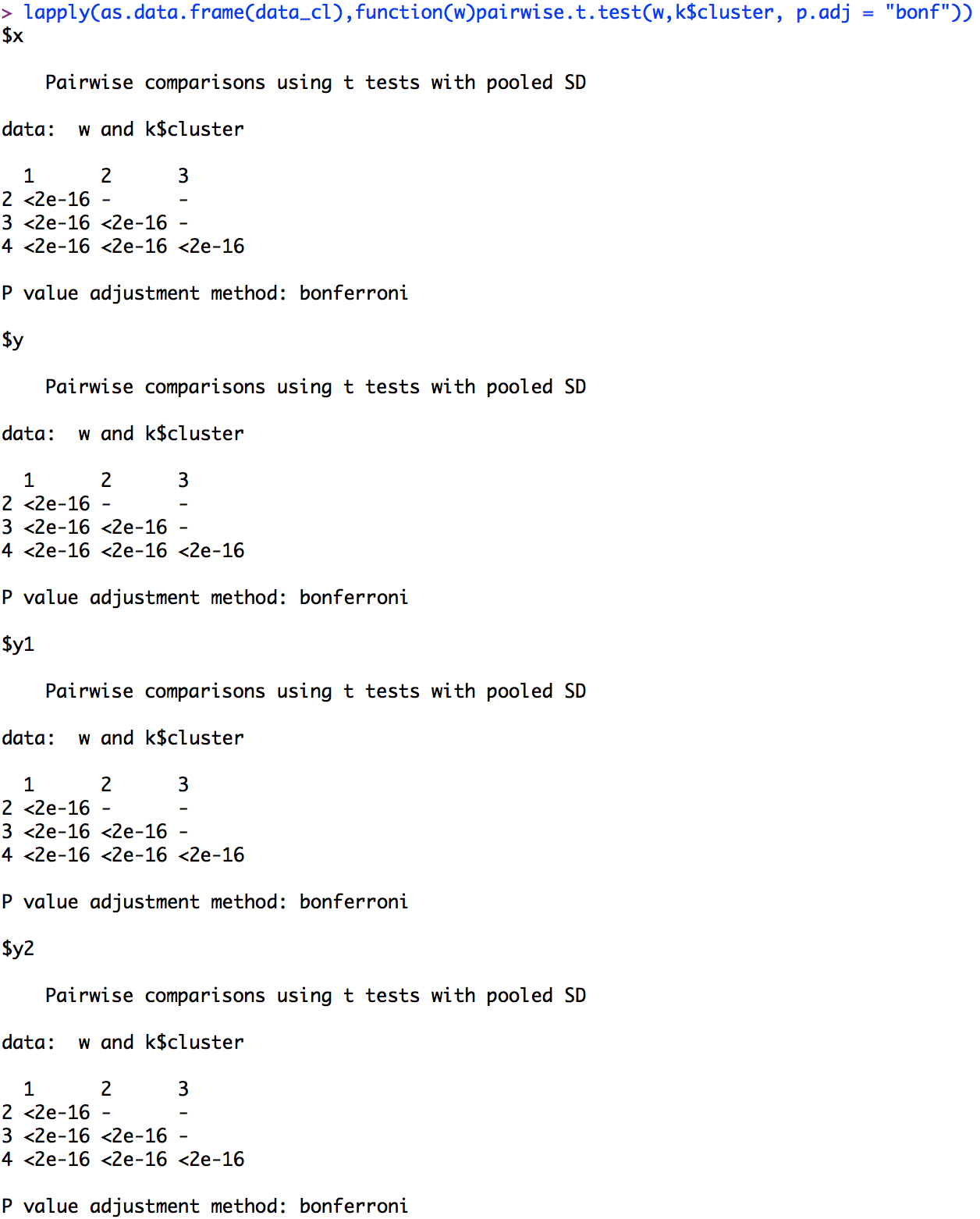
全て多重比較も行ってくれて完璧ですね!!



コメント
コメントを投稿