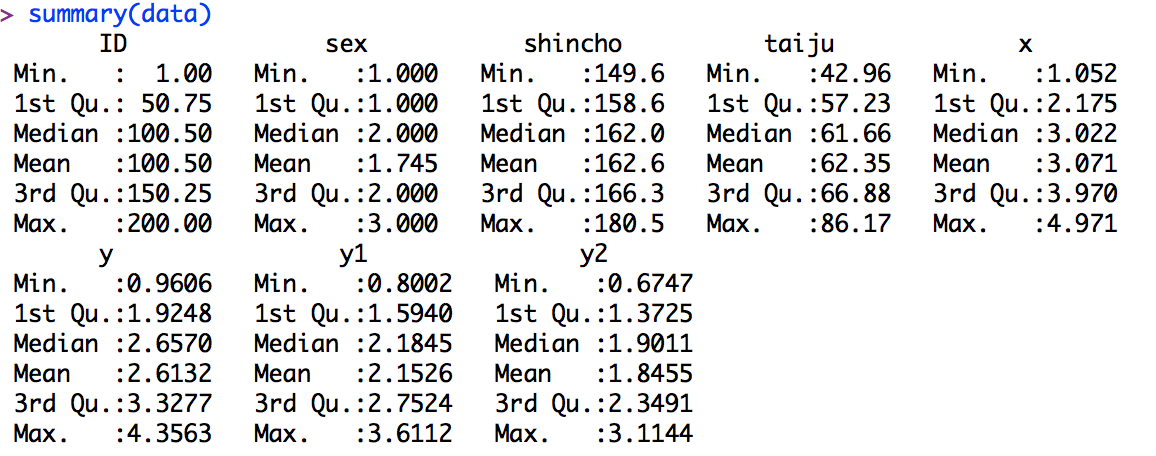
X2検定
###########X2検定####################
#2*2のX2検定
matrix(c(14,110,97,44),ncol=2,byrow=T)
chisq.test(matrix(c(14,110,97,44),ncol=2,byrow=T))
chisq.test(table(a1,a3))
my.fisher(matrix(c(14,110,97,44),ncol=2,byrow=T))
#2*1のX2検定
chi<-c(14+44,110+97)
chisq.test(chi)
#以下の式でも同じ
chisq.test(c(14+44,110+97))
オプションについて
correct=TRUE:イェーツの連続修正を行う
#前後(繰り返し)がある場合は以下の式を用いる。
mcnemar.test
0のセルがある場合や、5以下のセルが複数存在する場合は、フィッシャーの正確確率検定を行う。
理論度数が、5よりも低い度数を含む場合、または、データセットの周辺度数(行ごとの合計または列ごとの合計)がとても異なっている場合、Fisher’の正確検定に頼るのがよい方法です。
カイ2乗検定はFisherの正確検定よりも強力(帰無仮説が偽である場合、それをより棄却しやすい)です。
fisher.test(x)
###############X2検定Part2####################
#2×2 分割表において,フィッシャーの正確確率検定を行う。
#R には fisher.test があるが,この関数では fisher.test が計算する Fisher の方法による P 値と同時に,Pearson の方法による P 値も計算する(オッズ比を基準にするものも計算する)。
#使用法
my.fisher(x)
#引数
#x 2×2 分割表を表す,2×2 行列
#ソース
#インストールは,以下の 1 行をコピーし,R コンソールにペーストする
source("http://aoki2.si.gunma-u.ac.jp/R/src/my_fisher.R", encoding="euc-jp")
# 2×2 分割表のフィッシャーの正確確率検定
my.fisher <- function(x) # 2×2 分割表
{
odds.ratio <- function(a, b, c, d) # オッズ比を求める関数
{
if (a*b*c*d == 0) { # セルのどれかが 0 の場合
a <- a+0.5 # それぞれに 0.5 を加える
b <- b+0.5
c <- c+0.5
d <- d+0.5
}
res <- a*d/(b*c) # オッズ比
return(max(res, 1/res)) # どちらか大きい方を返す
}
stats <- function(i) {
e <- (a <- i[1]) + (b <- i[2])
f <- (c <- i[3]) + (d <- i[4])
n <- (g <- a+c) + (h <- b+d)
return(c(n*(a*d-b*c)^2/(e*f*g*h), # カイ二乗値
odds.ratio(a, b, c, d), # オッズ比
exp(lchoose(e, a)+lchoose(f, c)-lchoose(n, g)))) # 生起確率
}
ct <- colSums(x) # 列和
rt <- rowSums(x) # 行和
n <- sum(x) # 総合計
mx <- min(rt[1], ct[1]) # a が取り得る最大値
mi <- max(0, rt[1]+ct[1]-n) # a が取り得る最小値
A <- mi:mx # a のベクトル
B <- rt[1]-A # b のベクトル
C <- ct[1]-A # c のベクトル
D <- ct[2]-B # d のベクトル
Cell <- cbind(A, B, C, D) # 行方向の 4 つの数値が一つの分割表
result<-apply(Cell, 1, stats) # 行方向の 4 つの数値に,stats 関数を適用
Chi.sq <- result[1,] # カイ二乗値ベクトル
OddsRatio <- result[2,] # オッズ比ベクトル
Probability <- result[3,] # 生起確率ベクトル
Cum.Prob1 <- cumsum(Probability) # 生起確率の累積和
Cum.Prob2 <- rev(cumsum(rev(Probability))) # 逆方向からの生起確率の累積和
Pearson <- Chi.sq >= stats(c(x))[1]-1e-15 # カイ二乗値から判定した P 値に算入すべきセル
Fisher <- Probability <= stats(c(x))[3]+1e-15 # フィッシャーの定義による P 値に算入すべきセル
OR <- OddsRatio >= stats(c(x))[2]-1e-15 # オッズ比から判定した P 値に算入すべきセル
p.Pearson <- sum(Probability[Pearson]) # カイ二乗値から判定した P 値
p.Fisher <- sum(Probability[Fisher]) # フィッシャーの定義による P 値
p.OR <- sum(Probability[OR]) # オッズ比から判定した P 値
return(list(result=cbind(Cell, Chi.sq, Probability, OddsRatio, Pearson, Fisher, OR, Cum.Prob1, Cum.Prob2), p.Pearson=p.Pearson, p.Fisher=p.Fisher, p.OR=p.OR))
}
#使用例
my.fisher(matrix(c(10, 13, 16, 61), nc=2, byrow=TRUE))
#出力結果例
> my.fisher(matrix(c(10, 13, 16, 61), nc=2, byrow=TRUE))
# 一行がそれぞれ,可能な2×2分割表
# A, B, C, D は各セルの値
# Chi.sq は,カイ二乗値(連続性の修正なし)
# Probability は,分割表の生起確率
# Pearson は,カイ二乗値が観察された分割表のカイ二乗値以上の場合に 1 を取る(Pearson の基準による)
# Fisher は,生起確率が観察された分割表の生起確率以下の場合に 1 を取る(Fisher の基準による)
# Cum.Prob1, Cum.Prob2 は両端からの累積確率(片側検定の時に利用できる)



コメント
コメントを投稿