基本作業編
##############基本作業編##################
setwd("ディレクトリ")
#ディレクトリの設定
data <- read.csv("ファイル名.csv")
#ファイルの読み込み
#注意)スラッシュの向きに注意
data2 <- na.omit(data)
#dataから欠損値のあるデータを行ごと削除して、data2 に代入
#データによっては、欠損処理によってサンプル数が減り過ぎるので、
#欠損処理のタイミングと方法には注意
count<-function(x)
{sum(!is.na(x))}
#データの欠損以外の個数を数える式
count(data$rikai)
by(data2$sex,data2$sex,count)
#by(データ名,群名,何をするか)
describeBy(データ名,group = data$sex)
#"group = グループ分けしたい変数名"
#グループ分けして、基礎統計量を出す
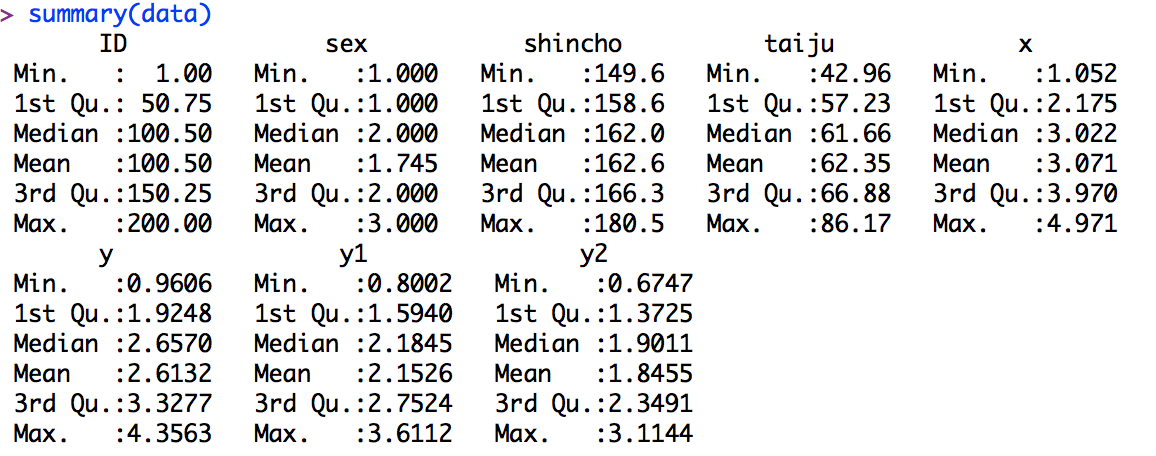
describe(data2)
#data2の基礎統計量を出す
ncol(x)
#行数
nrow(x)
#列数
data2_m<-subset(data2,sex==1)
data2_f<-subset(data2,sex==2)
#data2からsex1.2ごとにそれぞれdata2_mとdata2_fに代入
#"&"でAND、"|"でOR
table(data$gra)
#度数分布
hist(data$gra)
#ヒストグラム



コメント
コメントを投稿