カテゴライズ
########カテゴライズ######################
#3郡に分ける。平均値±1/2SDで区切る
data_n <- data2_uwaki_n0
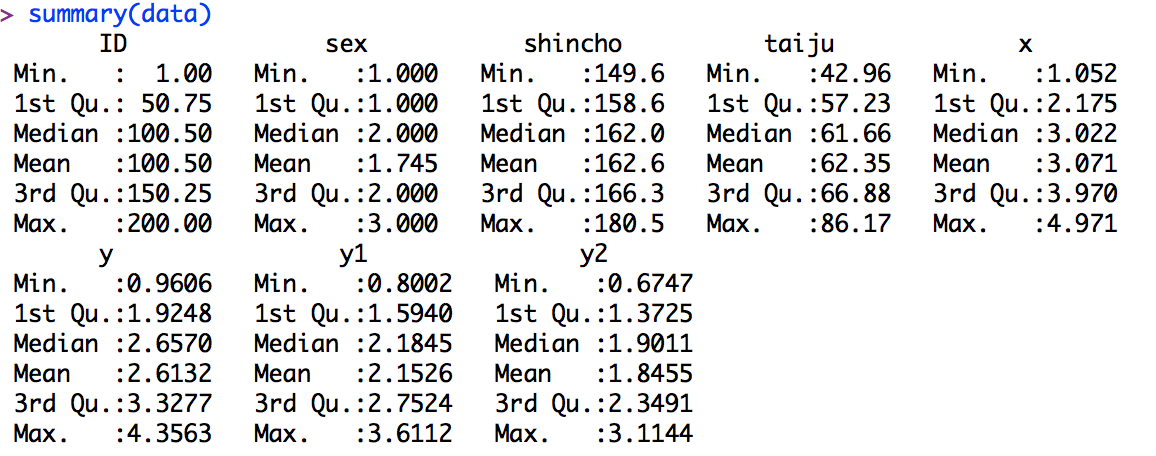
describe(data_n)
result<-describe(data$data$a01)
low<-result$mean-0.5*result$sd
high<-result$mean+0.5*result$sd
data$a01_cate[data$a01<=low]<-1
data$a01_cate[data$a01>low&data$a01<high]<-2
data$a01_cate[data$a01>=high]<-3
##############cut関数(カテゴリライズ)
cut(データ名,breaks=c(0,80,100), labels=c("不合格","合格"), right = FALSE, include.lowest = TRUE)
#breaks=c(0,80,100)←区切り位置の指定(ラベル数よりも1つ多くなる)
#right ←デフォルトは(TRUE)
#0は入らず80まで(以下)、80は入らず100まで
#FALSEだと、0から80未満、80以上100未満
#include.lowest = TRUE ← right = FALSEの場合は100がカテゴリに含まれないため、100(上限)をカテゴリに含む設定
私は個人的にcut関数が好きですが、”以上”や”未満”の設定が面倒なのと、
柔軟性にかける部分もあると思うので(私の勉強不足かもしれませんが...)
上段に記載した方法が、アンパイです。



コメント
コメントを投稿