Rで非階層的クラスター分析をやる
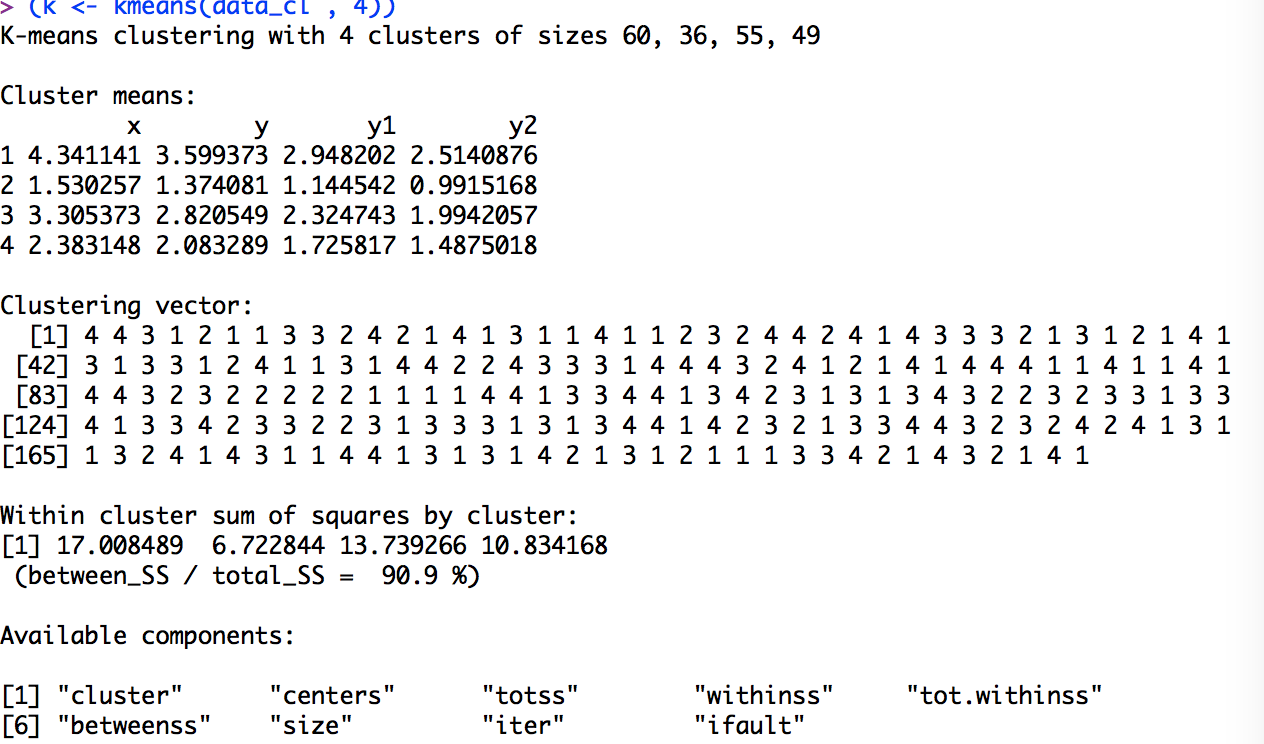
前回、階層的クラスター分析を紹介したので、今回は非階層的クラスター分析を行います。 先行研究でクラスター数が分かっている、もしくは想定される場合は非階層的クラスター分析から開始できますが、そうでない場合は階層的クタクター分析でクラスター数に目安をつけておく必要があります。 今回は、前回行った階層的クラスター分析の結果を元にやっていきます。 ここから、見て意味が分からない方は前回の階層的クラスター分析を見てください。 前回、x.y.y1.y2の4つの変数で、参加者が4群に分かれそうなことが分かりました。 そこで、実際にどのような4群なのかを見ていきましょう。 今回は非階層的クラスター分析をplyrパッケージのkmeans関数を用いて行います。 まず、いつも通りパッケージのインストールと読み込みを行います。 install.packages("plyr”) library(plyr) 前回と同じく、クラスター分析したい項目だけのデータセットを作成します。 data_cl <- data[,c("x","y","y1","y2")] そして、kmeans関数で分析を実行させます。 (k <- kmeans(data_cl , 4)) 式全体が()で括られているのは、分析結果をkというオブジェクトに代入しているので、そのままでは結果が表示されないため、結果を呼び出すためのものです。 kmeans関数の基本は以下のようになっています。 基本式:kmeans(データフレーム,クラスター数) 以下、任意のオプション iter.max : 繰り返しの最大回数。デフォルトは N=10。 nstart : ランダムに初期値を設定する場合のパラメータ。初期値を変更したい場合に用いる。試行回数。何通りの初期値を設定するかを指定する。k-means法は初期値依存という短所があります。そのため、時間とPCのスペックが許す限りnstartの回数を大きくした方が良いようです。初期値は最大でサンプル数-1までだと思います。同じ条件式で複数回分析を行い結果が同じであればさらに万全です。 alg...