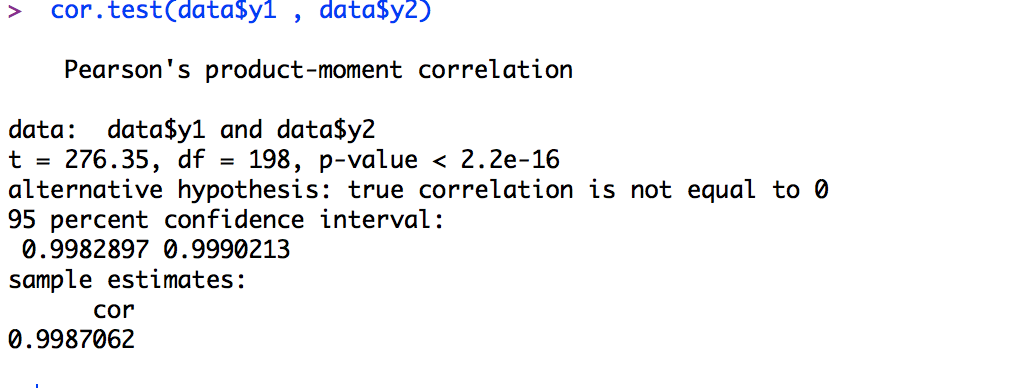
相関係数を先日紹介しましたが、無相関検定の事を書き忘れていました。 無相関係数の帰無仮説は「相関係数が0である」となります。 つまり、無相関検定で分かることは「相関関係があるかどうか」であって相関の強さの程度が分かるものではありません。 という事で、あまり個人的には使うことのない検定だと思います。 相関係数はt検定などと違い関係性の強さが分かる検定なので、相関関係があるかどうかよりもどの程度あるかが大切です。 無相関検定を使う時は、相関係数が小さく相関関係があると言えるかどうか微妙な時だと思います。 前置きが長くなりましたが、無相関検定の使い方は簡単です。 以下の通りです。 cor.test(変数1,変数2) 実際に使ってみると、下記図のようになります。 ここで言っている無相関検定はパーソンズの無相関検定なので、最初の行にそれが書いてあります。 最低限見るべきポイントは、 p-value:P値 cor:相関係数 今回の例では、0.01%水準で相関関係があると言えますね。 まぁ、相関係数が.998なので当然ですが。 ちなみに、RやExcelで2.2e-16はと表示された場合は、0.00000000000000022ということです。 eはエラーを意味していて、表示しきれない0が何個あるかという事を示しています。 2e5だったら、200000 2e-5だったら、0.00002を示しています。 無相関検定の厄介なところは、相関係数のように一気に算出できないことです。 1つひとつ算出しなければなりません。 しかし、for関数を使えばなんとかなりますが、それはいつか書こうと思います。