anovakun
#######anova kun##########
source("anovakun_480.txt")
#anovakunを読み込む
#anovakunのデータを指定したディレクトリに入れておく必要がある。
#anovakunのファイル名は、versionにより異なるようなので、自分の持っているanovakunが入ったファイル名を確認してください。
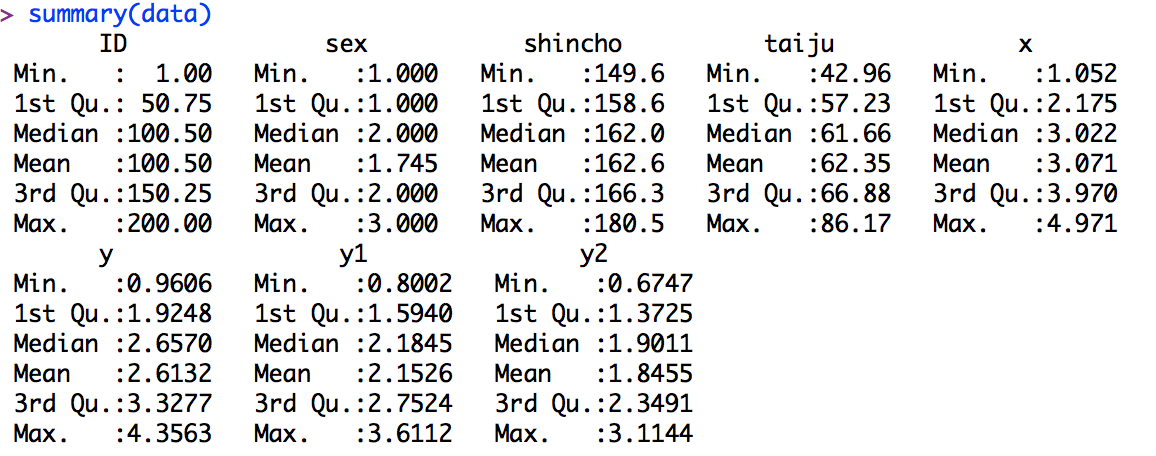
aov_1<-data[,c("要因A","要因B","従属変数")]
#分析専用のデータセットを作成、データセットの最後が従属変数になる
#注)分析ごとにデータセットを作らなければならない
anovakun(データセット,"要因計画",水準数,holm=T,peta=T)
#anovakun(データフレーム名,要因により変わる(*1),水準数,多重比較(ホルム法)の有無,効果量の指標の設定)
#(*1):2要因だとAB,3要因だとABC
#被験者間←s→被験者内
(例
1要因被験者内:sA
2要因被験者間:ABs
3要因混合計画:ABsC
#要因計画の書き方-> 被験者間要因は「s」の左側,被験者内要因は「s」の右側に配置します。
#例えば,2要因の被験者間計画は「ABs」,3要因の被験者内計画は「sABC」
#水準数の書き方はデータセットの要因の順番に対応する
#要因の指定の関係で、被験者内要因を最後にデータセットを作成する必要がある。
##以下、オプションについて##
#holm・・・「holm = T」とすることで,Holmの方法(Sequentially Rejective Bonferroni Procedure)を指定できます。Shafferの方法よりも若干検出力が落ちますが,使用に際しての制約がより少なく,広い場面で適用できる方法です。
#hc・・・「hc = T」とすることで,Holland-Copenhaverの方法(Improved Sequentially Rejective Bonferroni Test Procedure)を指定できます。Shafferの方法よりも若干検出力が高まりますが,相互に相関のあるデータ(反復測定データ)に適用することの妥当性は明確にされていません。
#s2r・・・「s2r = T」とすることで,RasmussenのアルゴリズムによるShaffer2の方法を指定できます。以下の方法ともども,くわしくは,Shafferの方法のバリエーションを参照してください。
#s2d・・・「s2d = T」とすることで,DonoghueのアルゴリズムによるShaffer2の方法を指定できます。
#fs1・・・「fs1 = T」とすることで,主効果(単純主効果)の結果を反映させたShaffer1の方法を指定できます。
#fs2r・・・「fs2r = T」とすることで,主効果(単純主効果)の結果を反映させたShaffer2の方法を指定できます(Rasmussenのアルゴリズム)。
#fs2d・・・「fs2r = T」とすることで,主効果(単純主効果)の結果を反映させたShaffer2の方法を指定できます(Donoghueのアルゴリズム)。
#welch・・・「welch = T」とすると,多重比較の際にKeselman-Keselman-Shafferの統計量とWelch-Satterthwaiteの近似自由度を使用します。Welchの方法を複数の要因を含むデザインや反復測定要因を含むデザインに拡張した方法に基づいており,等分散性や多標本球面性が成立しない場合により適切な手法です(Keselman et al., 1991)。
#criteria・・・「criteria = T」とすると,多重比較の結果の出力時に,調整済みp値の代わりに調整後の有意水準を表示します。
#結果の読み方
#<< DESCRIPTIVE STATISTICS >>・・・条件ごとの平均値、標準偏差
#A、Bなどは要因計画のところと同じ
#1、2の数字はデータに出てきた順番になる?
#以下のような命令でデータ数を確認することもできる
tapply(data$従属変数,list(data$独立変数1,data$独立変数2,…),mean)
#<< ANOVA TABLE >>・・・分散分析表
#dfが自由度(2つ目の自由度は常にErrorのところ)、F-ratioがF値、p-valueが有意確率
#A、Bが主効果、A × Bが交互作用(2要因の場合)
#<< POST ANALYSES >>・・・多重比較など
#主効果、交互作用がともに有意でなければ出力されない
#主効果が有意:< MULTIPLE COMPARISON for "A" >・・・Aについての多重比較
#t-valueがt値、dfが自由度、adj.pが有意確率
#一番右が等式なら有意差なし、不等式なら有意差あり
#交互作用が有意:< SIMPLE EFFECTS for "A x B" INTERACTION >・・・AとBの単純主効果の検定
#"A at b1"などは"b1におけるA"という意味
#たとえばAが性別、Bが学年(b1が1年、b2が2年、b3が3年)だとすると、
#1年だけで見た場合に性別による差はあるのかという検定
#dfが自由度(2つ目の自由度は常にErrorのところ)、F-ratioがF値、p-valueが有意確率
#単純主効果が有意:< MULTIPLE COMPARISON for "A at b1" >・・・b1におけるAについての多重比較
#Aが3水準以上の場合のみ出力される
#t-valueがt値、dfが自由度、adj.pが有意確率
#一番右が等式なら有意差なし、不等式なら有意差あり
#要因計画、要因数によって出力が異なる(ここまでの説明は2要因被験者間計画を想定)
#(anova君を作った人のホームページ)



コメント
コメントを投稿